cs-study-01 | 정렬, 탐색알고리즘
순서
정렬알고리즘
- 삽입정렬 (삽입법)
- 셸정렬 (삽입법)
- 선택정렬 (교환법)
- 버블정렬 (교환법)
- 퀵정렬 (교환법)
- 힙정렬 (선택법)
- 병합정렬 (병합법)
| Name | Best | AVG | Worst | 안정 | 메모리 |
|---|---|---|---|---|---|
| 삽입정렬 | O(n) | O(n^2) | O(n^2) | O | O(1) |
| 선택정렬 | O(n^2) | O(n^2) | O(n^2) | X | O(1) |
| 버블정렬 | O(n^2) | O(n^2) | O(n^2) | O | O(1) |
| 셸 정렬 | O(n) | O(n^1.5) | O(n^2) | X | |
| 퀵 정렬 | O(nlogn) | O(nlogn) | O(n^2) | X | O(logn) |
| 힙 정렬 | O(nlogn) | O(nlogn) | O(nlogn) | X | O(1) |
| 병합정렬 | O(nlogn) | O(nlogn) | O(nlogn) | O | O(n) |
삽입정렬
Insertion Sort

2번째 원소(key)부터 시작하여 그 앞(왼쪽)의 원소들과 비교하여 삽입할 위치를 지정한 후, 원소를 뒤로 옮기고 지정된 자리에 자료를 삽입하여 정렬하는 알고리즘
(key값이 앞 자리로 교체할 때마다 1회전 증가)
장점
- 알고리즘이 단순하여 구현이 쉽다
- 정렬하고자 하는 배열 안에서 교환하는 방식으로 다른 메모리 공간을 필요로 하지 않는다 (제자리 정렬: in-place sorting)
- 안정 정렬(Stable Sort)이다
단점
- 평균과 최악의 시간복잡도를 보아 배열의 길이가 길어질수록 비효율적이다
선택정렬
Selection Sort

해당 자리(key)로 옮길 원소를 뒤(오른쪽)에서부터 끝까지 탐색하면서 가장 작은 값을 찾아 교환하는 알고리즘
(key값이 고정될 경우 1회전 증가) —-> 이래서 최선도 O(n^2) 인듯…?
장점
- 알고리즘이 단순하여 구현이 쉽다
- 비교 횟수는 많지만 , Bubble Sort에 비해 실제로 교환하는 횟수는 적기 때문에 많은 교환이 일어나야 하는 자료상태에서 비교적 효율적이다
- 정렬하고자 하는 배열 안에서 교환하는 방식으로 다른 메모리 공간을 필요로 하지 않는다(제자리 정렬:in-place sorting)
단점
-
매번 끝까지 탐색하면서 비교하므로 최선,평균,최악 O(n^2)로 비효율적이다
-
불안정 정렬(Unstable Sort) 이다
버블정렬
Bubble Sort

서로 인접한 두 원소를 비교하고 조건에 맞지 않는다면 자리를 교환하며 정렬하는 알고리즘
(인접한 두 원소를 비교하여 교환하는게 배열 끝까지 갔을 경우 1회전증가)
장점
- 알고리즘이 단순하여 구현이 쉽다
- 정렬하고자 하는 배열 안에서 교환하는 방식으로 다른 메모리 공간을 필요로 하지 않는다(제자리 정렬:in-place sorting)
단점
- 매번 끝까지 탐색하면서 비교하므로 최선,평균,최악 O(n^2)로 비효율적이다
- 교환연산이 많이 이뤄진다
퀵정렬
Quick Sort
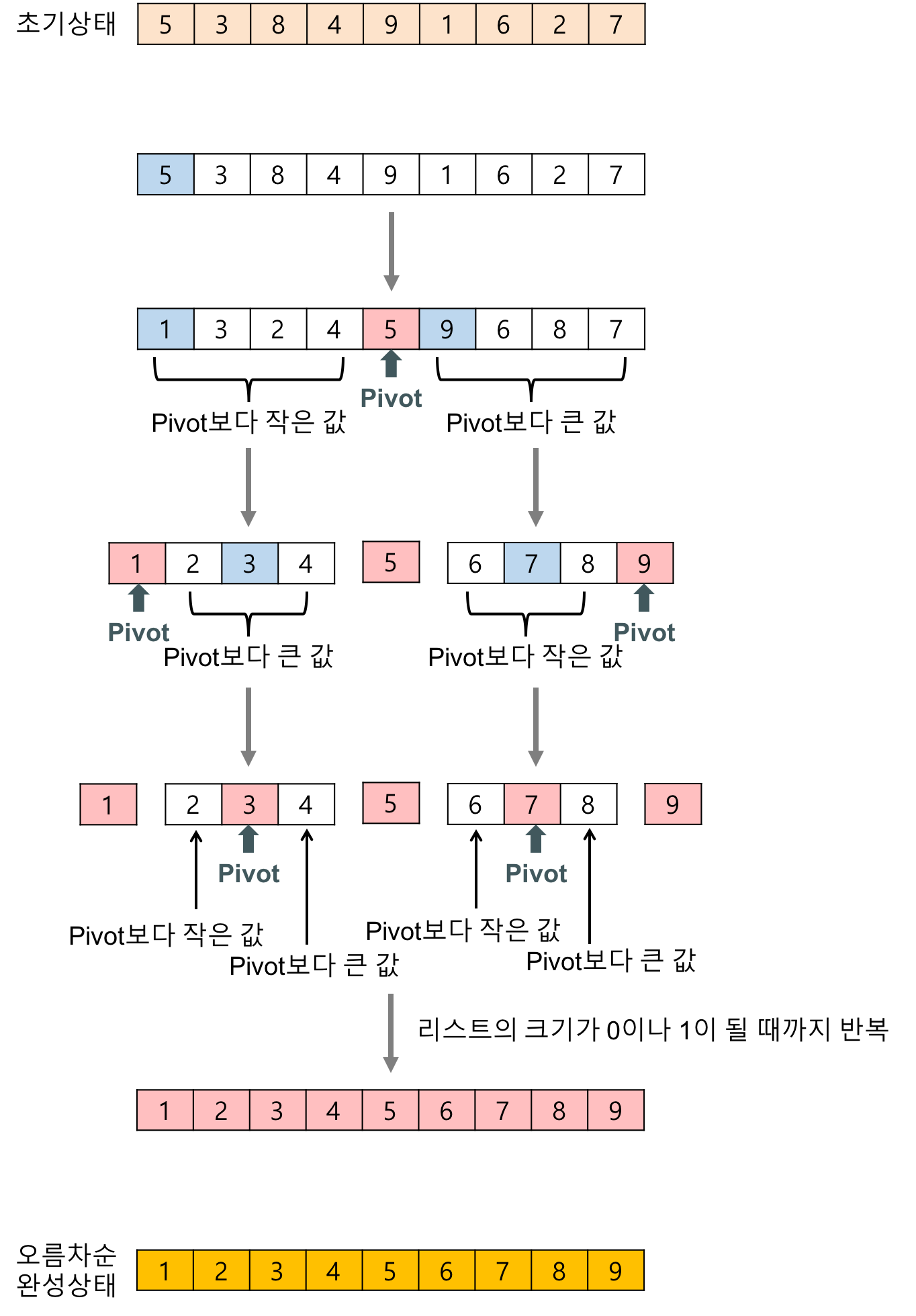
전체를 분할기준(pivot)보다 작은 구간, 큰 구간으로 나누는 작업을 재귀적으로 수행하여 정렬하는 알고리즘
(pivot을 기준으로 쪼개졌을경우 1회전 증가)
① pivot을 정한다 (random, 첫번째, 중간, 마지막 … )
② (위치변수) left ++ , right– 하면서 left에다가는 pivot보다 큰 수의 위치, right에다가는 분할기준(pivot)보다 작은 수의 위치를 저장하고 교체한다
③ right이 left 와 같거나 작을 경우 right이 pivot보다 작을경우 값을 변경해준다
④ right 위치가 pivot이 되고 분할되어 반복한다
장점
- logn만큼 분할하고 분할마다 최대 n번 데이터 비교가 발생하므로 시간복잡도가 O(nlogn) 이므로 속도가 빠르다
- 정렬하고자 하는 배열 안에서 교환하는 방식으로 다른 메모리 공간을 필요로 하지 않는다(제자리 정렬:in-place sorting)
단점
- 최악의 경우 : pivot이 매번 제일 크거나 작은 값을 선택될 때 , 이미 정렬된 데이터에 대해서 퀵 정렬을 수행할 때 (해결하기 위해 중간값을 pivot으로 선택한다)
- 불안정 정렬(Unstable Sort) 이다
힙정렬
Heap Sort
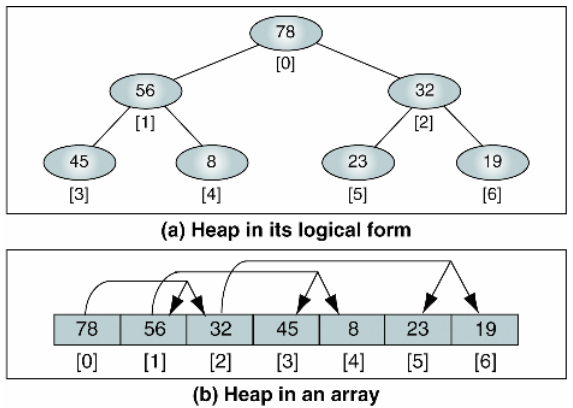
완전 이진 트리 형태로 최대힙일 경우에는 내림차순으로, 최소힙일 경우에는 오름차순으로 정렬하는 알고리즘
최대힙일 경우 부모노드 >= 자식노드 @@@ 최소힙일 경우 부모노드 <=자식노드
인덱스가 0부터 시작한다고 가정할 경우 :: 부모노드(n)일 경우 왼쪽자식노드(2n+1) , 오른쪽자식노드(2n+2)
[최대힙일 경우 정렬방법]
① root값을 빼준다
② 힙의 마지막 노드를 root로 올린다
③ 자식노드와 비교하며 큰 값을 부모노드로 교환한다
④ 모든 노드가 빠질 때까지 반복한다
장점
- 전체 자료를 정렬하는 것이 아니라 가장 크거나 작은 값 몇개만 필요할 경우 유용하다
단점
- 불안정 정렬(Unstable Sort) 이다
병합정렬
Merge Sort
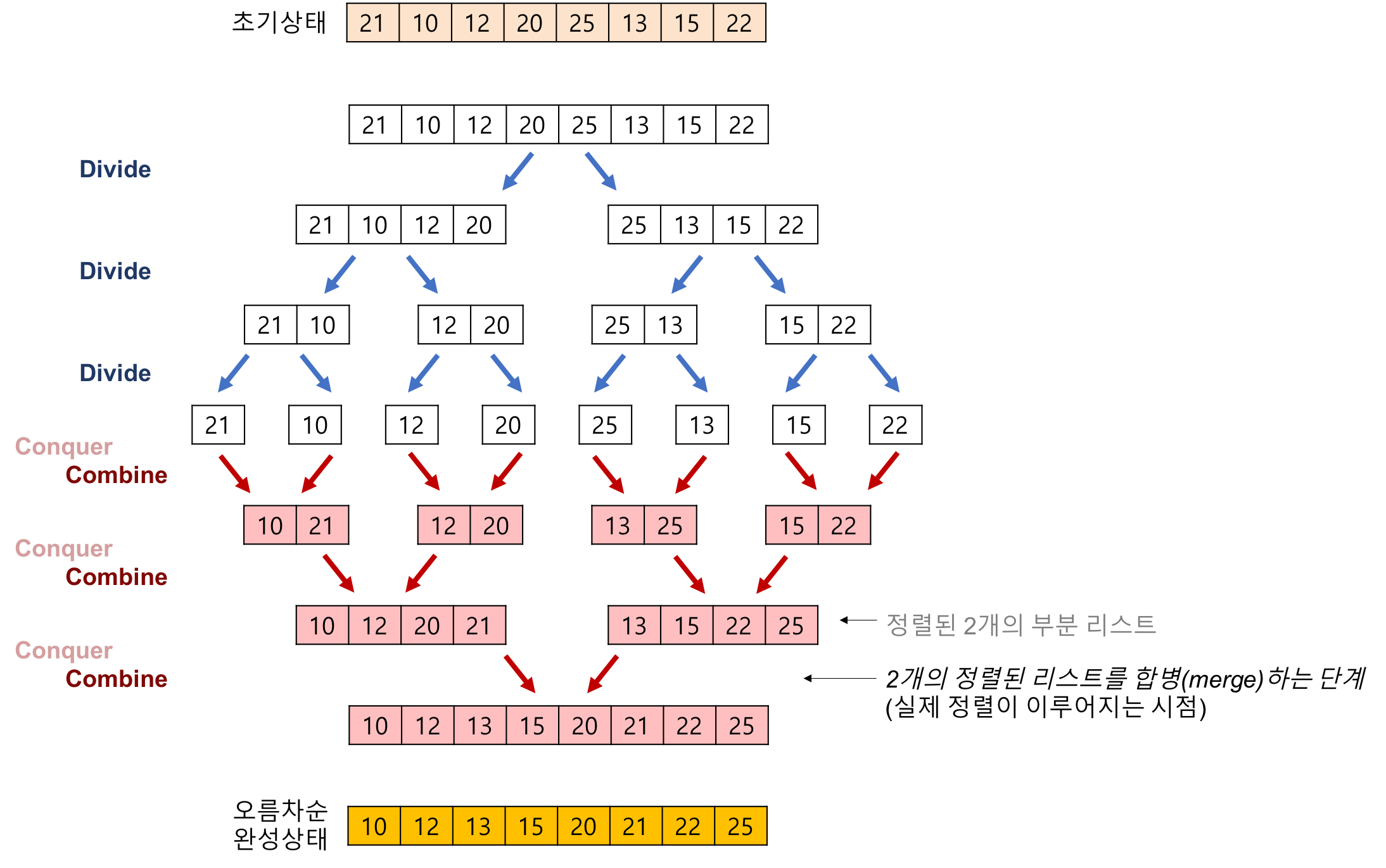
원소를 하나일 때까지 절반씩 쪼갠 후 다시 합병시키면서 정렬하는 알고리즘
(인접한 두 원소를 비교하여 교환하는게 배열 끝까지 갔을 경우 1회전증가)
장점
-
안정 정렬로 입력 데이터가 무엇이든 간에 정렬되는 시간은 동일하다
-
데이터셋을 연결리스트로 구현하면 링크 인덱스만 변경하면 되므로 제자리 정렬로 구현할 수 있다
단점
- 거대한 데이터 셋일 경우 이동횟수가 많아지므로 매우 큰 시간적 낭비를 초래한다
- 제자리 정렬이 아니다
- 정렬 결과를 저장할 배열을 새로 만들고, 이를 기존에 배열에 복사하므로 거대한 데이터 셋에서 치명적이다
(추가) 안정정렬,불안정정렬

안정정렬: 동일한 값에 기존 순서가 유지
불안정정렬: 동일한 값에 기존 순서가 유지하지 않는다
탐색알고리즘
- 선형탐색
- 이진탐색
- 해시탐색
- 이진탐색트리
선형탐색
Linear Search
맨 앞이나, 맨 뒤에서부터 순서대로 하나씩 찾아보는 알고리즘
장점
- 단순하고 이해하기 쉽고 구현하기 쉽다
단점
- 데이터 수에 따라 시간이 늘어나므로 비효율적이다
시간복잡도 : O(n)
최선인 경우 : 리스트의 첫 번째 원소가 정답인 경우 O(1)
최악의 경우 : 리스트의 맨 마지막 원소이거나 찾는 값이 없을 경우 O(n)
이진탐색
Binary Search
탐색 대상인 데이터가 미리 정렬되어 있을 경우 사용할 수 있다. 가운데 요소보다 큰지 작은지 조건에 맞춰 탐색범위를 점점 좁힌다
장점
- 선형탐색은 n이 증가함에 따라 시간복잡도가 선형적으로 증가하지만 , 이진탐색은 n이 증가해도 비교적 천천히 증가한다
단점
시간복잡도 O(logn)
최선인 경우 : 리스트의 가운데 요소일 경우 O(1)
최악의 경우 : 리스트에 찾는 값이 없을 경우 O(logn)
해시탐색
Hash Search
index와 그에 해당하는 값을 연결해 둠으로써 짧은 시간에 탐색할 수 있는 알고리즘
해시값 : 데이터를 넣을 index 번호 (=데이터 % 배열크기)
장점
- 데이터를 저장하거나, 탐색하고자 하는 위치를 즉시 참조할 수 있기 때문에 빠른 속도로 처리가 가능하다
- 효율적으로 배열을 사용할 수 있다
단점
이진탐색트리
BST : Binary Search Tree
모든 노드의 키가 유일한 트리 자료구조를 이용해 탐색하는 알고리즘
원하는 값 > root 값 : 오른쪽 서브트리로 이동
원하는 값 < root 값 : 왼쪽 서브트리로 이동
원하는값 = root 값 : 탐색 종료
장점
단점
추가알고리즘
- 분할정복 알고리즘
- 그래프 알고리즘 (dfs,bfs,다익스트라,플로이드와샬)
시간복잡도
참조지역성 원리를 얼마나 잘 만족하는가
Reference
https://gmlwjd9405.github.io/2018/05/10/algorithm-quick-sort.html